Agentic AI Strategy
The anatomy of Agent Intelligence Fabric — four layers, not one
Logs tell you an agent ran. They do not tell you whether it behaved well. Building real AI observability means four distinct layers — and most teams only build one.
The anatomy of Agent Intelligence Fabric — four layers, not one
Post 2 of 6 in the Agent Intelligence Fabric series.
Beyond logs
When enterprises talk about AI observability, they almost always mean one thing: logs.
Logs are necessary. They are not sufficient.
Logging that an agent was invoked, made three API calls, and returned a response tells you almost nothing about whether the agent behaved well. It doesn’t tell you what information it had, how it reasoned, what it decided to do, or whether that decision produced the outcome you intended.
A flight recorder isn’t a list of timestamps. It captures altitude, airspeed, engine state, control surface inputs — the full operational context that allows investigators to reconstruct what happened and why. Agent observability needs the same depth.
The Agent Intelligence Fabric introduced in Post 1 is built on four distinct layers. Each answers a different question. Each serves a different organisational stakeholder. And each builds on the previous — you cannot get layer 4 right without layers 1 through 3 underneath it.
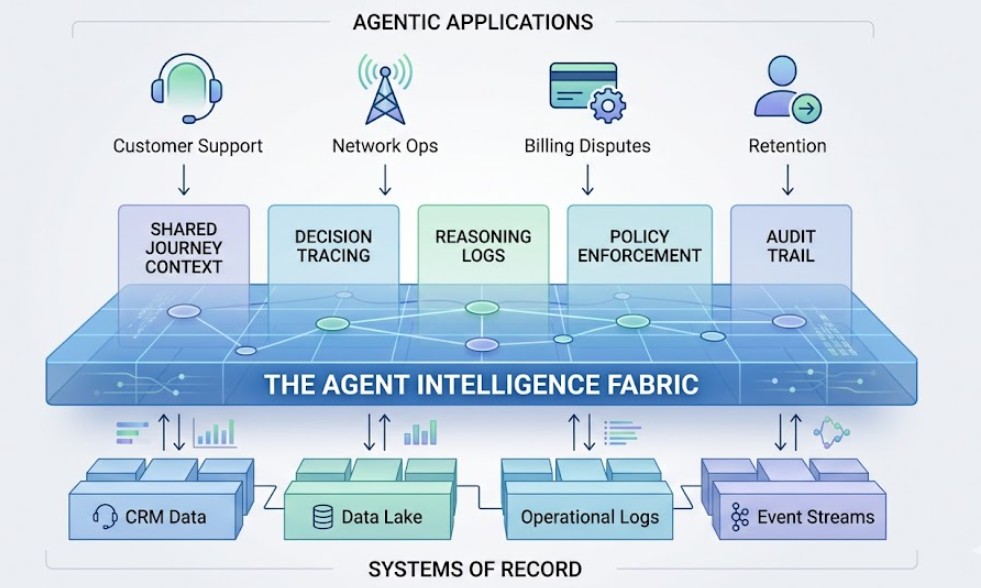
Layer 1: Invocation records
This is the substrate. Every tool call, API request, database query, and external service invocation the agent makes should be logged with:
- Input parameters and payload
- Response data and status
- Latency and token consumption
- Cost attribution — LLM tokens, API fees, compute
- Timestamp and sequence identifier linking back to the parent interaction
Invocation records answer the question: what did the agent do?
They’re the layer most teams have. They’re necessary for debugging, cost management, and basic audit trails. But they tell you nothing about reasoning or intent — which means they’re insufficient for any accountability use case beyond “did the agent run?”
Who needs this: Engineering, DevOps, FinOps. Cost-per-interaction calculations begin here.
Layer 2: Reasoning traces
This is the layer that separates a genuine observability platform from a log aggregator.
Modern AI agents — particularly those using LLMs as reasoning engines — produce intermediate outputs as part of their decision process: the chain-of-thought, sub-task decompositions, intermediate answers, confidence assessments, and the reasoning that connects input context to final action.
Capturing these traces allows you to reconstruct why the agent chose a particular action. When a support agent decides to escalate rather than resolve autonomously, the reasoning trace tells you which signals triggered that decision. When a billing agent issues a credit, the trace shows what policy it applied and what customer context it weighted.
This layer serves three purposes in practice:
Debugging — when an agent produces an unexpected output, reasoning traces let you pinpoint where the logic broke down without running blind experiments to reproduce the error.
Bias and fairness auditing — if agents make systematically different decisions for different customer segments, reasoning traces make that pattern visible and investigable.
Model improvement — traces are training signal. Consistently poor reasoning paths can be identified, labelled, and used to improve the underlying model or prompting strategy.
Who needs this: ML engineers, product managers, compliance, anyone doing root-cause analysis.
Layer 3: Decision logs
Reasoning traces are rich but unstructured. Decision logs are their structured counterpart.
A decision log entry captures:
- The action taken (“issued $40 service credit”)
- The confidence score or certainty estimate
- The policy constraints that governed the action
- Whether a human override occurred
- The agent version and configuration active at the time
Decision logs are what compliance and legal teams need. When a regulator asks “what did your AI decide, and under what authority?” — the decision log is the answer.
Under the EU AI Act, organisations deploying AI in high-risk categories must maintain records of automated decisions, including the logic applied and the human oversight mechanisms in place. Decision logs are the technical implementation of that requirement. Building them as an afterthought — after a regulatory enquiry has already been filed — is a significantly more expensive approach than building them correctly from the start.
Who needs this: Compliance, legal, risk, executive stakeholders who need to attest to AI governance.
Layer 4: Outcome attribution
This is the layer most teams don’t build — and the one that matters most for sustained organisational investment in AI.
Outcome attribution links each agent decision to a measurable downstream business result:
- Did the retention offer prevent churn? Track 90-day retention for customers who received the intervention versus a holdout group.
- Did the automated billing correction reduce escalation rate? Compare ticket volumes before and after.
- Did AI-assisted network fault triage reduce mean-time-to-repair? Measure MTTR for AI-triaged incidents versus manually triaged equivalents.
Without this layer, AI ROI is anecdotal. Programme leaders present optimistic attribution — crediting the agent for every positive outcome in its intervention group — which inflates apparent returns and eventually produces investment decisions based on noise.
With outcome attribution built properly, AI becomes a measurable operational capability. One that can justify expansion based on evidence, identify underperforming agent types based on data, and defend investment to boards and CFOs with something more credible than a case study.
Building this layer requires integrating the agent fabric with downstream systems — CRM, billing, NOC ticketing, NPS survey platforms — and establishing the causal linkages between agent decisions and the events that follow. This is genuinely hard data engineering work. It requires clear metric definitions, baseline establishment, and often a period of controlled experimentation to separate agent impact from background trends.
It is worth doing properly. This is the layer that transforms AI from a cost item into a value driver in financial reporting.
Who needs this: Finance, product leadership, anyone who needs to answer “is this AI actually working, and by how much?”
The tamper-evidence requirement
One architectural principle applies across all four layers: tamper-evidence.
Agent logs that can be modified after the fact are not audit trails. They’re notes. For compliance, legal proceedings, customer disputes, and regulatory review, the integrity of the record matters as much as its content.
Leading implementations use cryptographic techniques — hash chaining, digital signatures — to ensure that any modification to a log record is detectable. This is not over-engineering. It is the difference between a record that can be presented as evidence and one that cannot.
What most teams get wrong
The most common failure mode in enterprise AI deployments is building Layer 1, calling it observability, and moving on to the next agent deployment.
The second most common failure is treating Layers 2 and 3 as engineering concerns rather than business concerns — implementing them without connecting them to the metric frameworks that would make them useful to compliance, finance, and product leadership.
The Agent Intelligence Fabric is not an engineering project. It is a cross-functional capability. The architecture decisions made at the start either enable or constrain every downstream use case — compliance review, ROI measurement, model improvement, regulatory audit.
Build all four layers. Build them as first-class concerns, not afterthoughts. The cost of retrofitting is always higher than the cost of building correctly from the beginning.
Next: Post 3 — Where agentic AI is producing real returns in enterprise operations, the specific risk profile in each domain, and what the Fabric must do to capture the upside safely.